Fraud Detection
Betrugserkennung mit neuronalen Netzwerken
Das Erkennen und Verhindern von Betrugsversuchen zählt zu den größten Schwierigkeiten im Onlinehandel. Der Betrug besteht darin, Ware aus einem Onlineshop zu beziehen, ohne diese zu bezahlen. Deshalb wurde die Betrugserkennung mit neuronalen Netzwerken entwickelt.
Das Internet bietet den Betrügern die Anonymität, um beim Agieren unentdeckt zu bleiben. Erschwerend für Onlinehändler kommt hinzu, dass deren Kunden einen immer kürzeren Zeitraum zwischen Bestellung und Erhalt der Ware wünschen. Dies führt zwangsläufig dazu, dass immer weniger Zeit für die Kontrolle von Bestellungen im Onlinehandel übrigbleibt.
Um sich diesem Problem anzunehmen, arbeiten wir bei piazza blu an einer Fraud Detection Lösung, die auf Machine Learning basiert. Diese kann aus den historischen Daten eines Onlineshops lernen, welche Merkmale einer Bestellung auf einen Betrug hindeuten. Die erkannten Muster aus den historischen Bestellungen können dann auf neue Bestellungen getestet und im Zuge dieses Tests klassifiziert werden.
Grundlage für die Betrugserkennung ist ein neuronales Netzwerk. Dieses wird mithilfe von überwachtem Lernen dahingehend trainiert, um aus historischen Bestellungen eines Onlineshops zu lernen und so zukünftige Bestellungen klassifizieren zu können.
Überwachtes Lernen
 Beim überwachten Lernen handelt es sich um eine Technik, bei der ein Lehrer ein bestimmtes Ergebnis für eine Ausgangssituation vorgibt. Im Fall der Bestellungen aus dem Onlineshop bedeutet dies, dass für jede historische Bestellung eine Vorklassifizierung erfolgt sein muss. Somit muss im Vorhinein bekannt sein, ob eine Bestellung einen Betrugsfall darstellt oder nicht.
Beim überwachten Lernen handelt es sich um eine Technik, bei der ein Lehrer ein bestimmtes Ergebnis für eine Ausgangssituation vorgibt. Im Fall der Bestellungen aus dem Onlineshop bedeutet dies, dass für jede historische Bestellung eine Vorklassifizierung erfolgt sein muss. Somit muss im Vorhinein bekannt sein, ob eine Bestellung einen Betrugsfall darstellt oder nicht.
Die Funktionsweise des Trainings, mit dem das neuronale Netzwerk angelernt wird, ähnelt hier einer Trainingsstunde für ein unerfahrenes Kind. Man kann sich vorstellen, dass einem Kind mehrere Bestellungen mit den jeweiligen Ergebnissen gezeigt werden – also: Ob eine Bestellung ein Betrugsversuch ist oder eben nicht.
Training der neuronalen Netzwerke mit numerischen Werten
Während des Trainings wird dann für jede Bestellung ein Ausgabewert vorgegeben. Die Ausgabewerte sind jeweils [0,1] und [1,0]. Diese stehen für „Betrug“ bzw. „Normaler Einkauf“. Mit jeder Bestellung wird dem neuronalen Netzwerk also aufgezeigt, welche Werte die Parameter der Bestellung besitzen und welcher Klasse die Bestellung somit zugeordnet werden kann.
Mithilfe des Backpropagation-Algorithmus ist das neuronale Netzwerk in der Lage, die Gewichtungen innerhalb des Netzwerkes so anzupassen, dass die Annäherung der vorgegebenen Klassifizierung verbessert wird. Diese Annäherung geschieht während des Trainings für eine Bestellung nur in kleinen Schritten, da alle Bestellungen berücksichtigt werden müssen.
Grafische Darstellung der Trainingsergebnisse
Die Trainingsergebnisse des neuronalen Netzwerks können mit Hilfe von tensorboard, einem Tool von tensorflow, grafisch dargestellt werden.
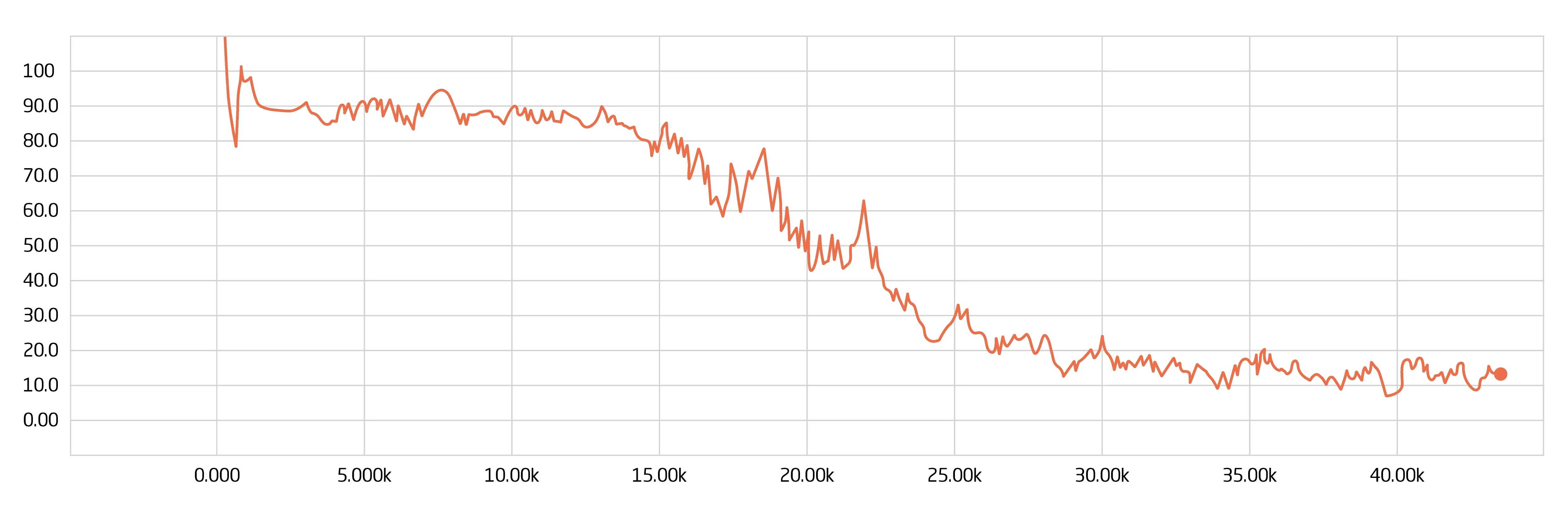
In Abbildung 1 ist zu erkennen, dass die Abweichung des Ergebnisses, welches das neuronale Netzwerk zu einer Bestellung ausgibt, zu dem gewünschten Ergebnis über die Iterationen des Trainings abnimmt. Die orangene Linie zeigt hierbei das Trainingsset, welches für das Anlernen genutzt wird.
Die Grafik verdeutlicht, dass das neuronale Netzwerk mit steigender Anzahl der Iterationen des Trainings einen immer kleineren Fehlerwert erzielt und somit immer besser in der Lage ist, die Bestellungen in die gewünschten Klassen einzuordnen. Zudem wird ab einem bestimmten Schwellenwert keine Verbesserung mehr erzielt. Das Training wird beendet, sobald keine Optimierung nach mehreren Iterationen mehr erzielt werden kann.
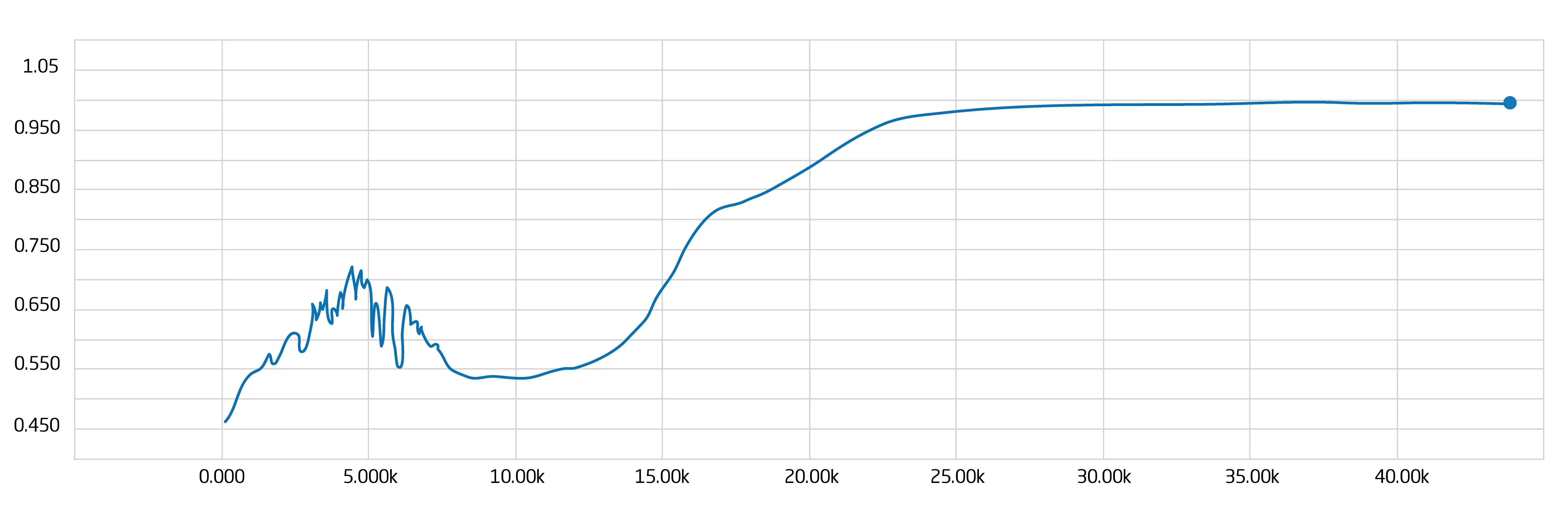
In Abbildung 2 bestätigt sich die Aussage, die man aus Abbildung 1 bereits ableiten kann. Hier ist zu sehen, mit welcher Genauigkeit das neuronale Netzwerk die Bestellungen aus dem Evaluationsset klassifizieren kann. Auch hier ist zu beobachten, dass mit ansteigender Anzahl von Iterationen im Training eine immer höhere Genauigkeit erreicht wird. Nach Abschluss des Trainings wurde das Evaluationsset final klassifiziert, um eine Genauigkeit zu ermitteln, mit der das neuronale Netzwerk die Bestellungen klassifizieren kann.
Richtige Klassifizierung des neuronalen Netzwerks
Die erreichte Genauigkeit auf den Trainingsdaten – also den prozentualen Wert an Bestellungen, die das neuronale Netzwerk richtig klassifizieren kann – lag nach dem Training bei etwa 96 %. Das neuronale Netzwerk kann unbekannte Bestellungen aus dem Onlineshop also mit einer Genauigkeit von 96 % klassifizieren. Bei 100 Bestellungen können also 96 richtig zugeordnet werden.
Da das Trainingsset zu je 50 % aus Betrugsfällen und 50 % aus normalen Einkäufen bestand, sind die durch das neuronale Netzwerk begangenen Fehlerarten ausgeglichen. Zur Testdurchführung wurde eine confusion matrix erstellt. Dafür wird ein weiteres Set an Bestellungen klassifiziert und für jede Bestellung notiert, welche Art von Fehler das neuronale Netzwerk erzeugt, wenn eine Bestellung falsch klassifiziert wurde.
Hierbei gibt es 2 Möglichkeiten:
Die Bestellung war ein Betrugsfall, jedoch wurde die Bestellung von dem neuronalen Netzwerk als normaler Einkauf klassifiziert Die Bestellung war ein normaler Einkauf, jedoch wurde die Bestellung von dem neuronalen Netzwerk als Betrug klassifiziert Mit Hilfe der confusion matrix können diese Fehlerarten genau berechnet werden. Dazu wird die Fehlerart des neuronalen Netzwerks pro Bestellung festgehalten. Die Werte der confusion matrix belegen, dass die Fehlerarten des neuronalen Netzwerks ausgeglichen sind. Somit ist die Anzahl der Betrugsfälle, die als normale Einkäufe klassifiziert wurden, in etwa gleich der Anzahl der normalen Einkäufe, die als Betrugsfälle klassifiziert wurden.
Gerne beantworten wir Ihnen noch offene Fragen zum Thema Fraud Detection oder unterbreiten Ihnen einen Vorschlag, wie wir die Betrugserkennung in Ihrem System integrieren können. Wir freuen uns von Ihnen zu hören!